
I've spent the last ~2 weeks working on my own agent and harness. It's been a great learning experience, and it's kind of shocking how capable you can get it with just a few simple concepts.
Why my own harness?
- It's fun
- I want to deploy it to Cloudflare inside a Durable Object so anything designed to run on a server is no-go
- I have no need for a UI, this is server only, so any TUI is bloat
- I am doing some crazy things
I had started with an off the shelf agent, but I just felt like there were so many things getting in the way that I was fighting the harness more than making progress.
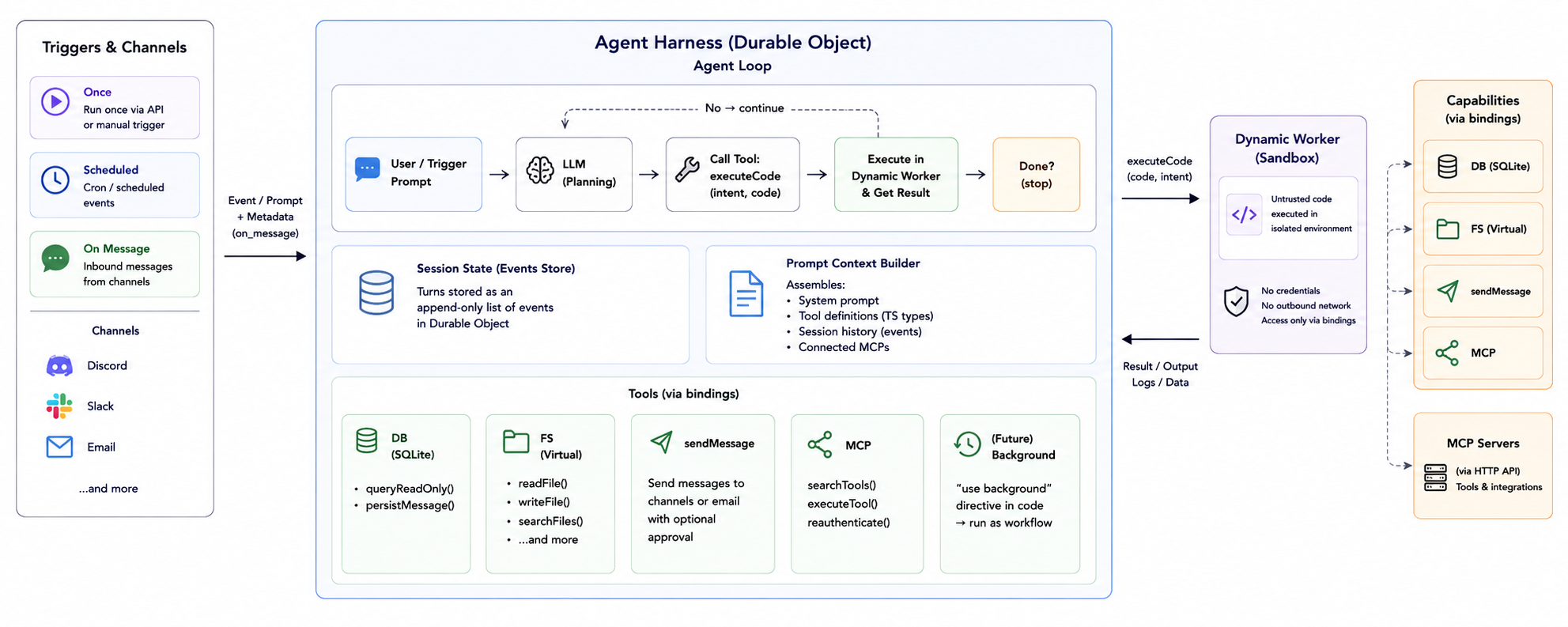
The shockingly simple architecture
My harness is only about ~300 LoC, which includes pretty much everything the agent needs to do. The most complicated part is actually handing streaming responses. It'll probably grow a little when I add the ability to swap out the LLM (currently only supports OpenAI compatible models, but plans to move away from that).
The core of the agent loop is essentially just 'call tools until you're done, then stop'. It stores turns as a list of events in a Durable Object.
Well... I say tools. The agent has ONE tool - 'executeCode'. The agent passes some JavaScript code in that tool, the harness executes it in a dynamic worker and then returns the result. It also passes an 'intent', which is a short, human readable string to explain what it is trying to achieve with this code. The intent is very useful for debugging, and showing progress to users.
Why JS?
Cloudflare supports JS, Python and WASM. The rest of the app is in TypeScript, so it makes sense to use it here. The other big advantage is it can do stuff like math, aggregations, parallel requests via Promise.all, and a whole bunch of things that you would otherwise need to build complicated tools and logic for. I remember the pain that came from trying to implement parallel tool calling natively.
Bindings
I use bindings to allow the worker to call functionality that I provide it. I give it a TypeScript definition for everything it can do – which is type-checked against my real code and inlined into the prompt via the Vite '?raw' helper. This also means the agent never gets access to any credentials and is limited only to data I provide it.
The agent has access to five simple things, which together have led to a whole bunch of emergent properties which I find incredibly powerful.
A SQLite Database
Each session gets a mirror of an SQLite database – in a Durable Object. This is a mirrored subset from a production database, and updated every 15 min. I don't trust it with my whole database yet, but it has a function it can call to do surgical updates. If it nukes the database (which hasn't happened yet), it will self heal and restore all the missing data.
There's also a fulltext index here, so it's able to search the data inside the database without having to load it all in memory.
DB: {
queryReadOnly(sql: string, params?: unknown[]): Promise<unknown[]>
persistMessage(input: Record<string, unknown>): Promise<{ ok: true; count: number }>
}
A file system
This is not a real file system. It's actually yet another Durable Object SQLite Database. But I pretend it's a file system, because it might be backed by R2 or Archil or whatever later.
My scorching hot take is that bash is overrated, and you only need JavaScript. I have the following functions it can call, and it can very easily figure it out:
FS: {
readFile(input: { path: string }): Promise<DynamicWorkerFileRecord>
writeFile(input: {
path: string
content: string
overwrite?: boolean
contentType?: string
expectedVersion?: number
hints?: { fileType?: string; intent?: string }
}): Promise<{ path: string; version: number }>
updateFile(input: { path: string; oldText: string; newText: string; expectedVersion?: number }): Promise<{ path: string; version: number }>
listFiles(input?: { prefix?: string; limit?: number }): Promise<DynamicWorkerFileEntry[]>
searchFiles(input: {
query: string
prefix?: string | null
topK?: number
type?: string | null
tags?: string[]
mode?: 'auto' | 'keyword' | 'semantic'
intent?: string | null
includeArchived?: boolean
}): Promise<DynamicWorkerFileSearchHit[]>
moveFile(input: { from: string; to: string; expectedVersion?: number }): Promise<{ path: string; version: number }>
loadFileIntoContext(input: { path: string }): Promise<{
path: string
loaded: true
contentType: string | null
extractionStatus: string | null
native: boolean
text: boolean
warning?: string
}>
deleteFile(input: { path: string; expectedVersion?: number }): Promise<void>
statFile(input: { path: string }): Promise<DynamicWorkerFileStat>
}
These functions should all be self-explanatory, except perhaps loadFileIntoContext. When this function is called, the harness takes the bytes from the file and shoves it into the user message for the LLM – which is useful for things like images or PDFs. But the agent can still read the file, and do things with it with JS.
searchFiles is particularly interesting. 'keyword' does what it says on the tin - looks for keywords in the files. 'semantic' again - does a vector search (powered by Cloudflare Vectorize).
'auto' is a little more complicated, but it essentially does a hybrid search. Keyword results and semantic search results get blended, then passed into a cheap LLM which does re-ranking. Intent allows the LLM that reranks to understand the purpose of the query - e.g. if searching for Nike, the agent can clarify it means the goddess.
A way to send messages
The agent has a function it can use to send messages. The prompt that comes in from a channel tells it where it's been called from, and it calls this function to reply to that channel. It can also call this function to autonomously do things.
It also has the discretion to say whether a message needs to be approved or not.
sendMessage(input: {
message: string
channel_id?: string
sender_id?: string
integration_type: 'discord' | 'slack' | 'email'
require_approval?: boolean
reply_to_id?: string
to?: string
subject?: string
html?: string
}): Promise<SendMessageResult>
Triggers
There are three kinds of triggers – once, scheduled and 'on_message'. The agent has a prompt that gets sent to a session in response to these events. 'on_message' events also include metadata about the action message.
MCP servers
This is where I've gone truly mad.
type McpBinding = {
searchTools(input?: { keywords?: string[] | string; server?: string | null }): Promise<McpToolSummary[]>
executeTool(input: { server: string; toolName: string; args?: unknown }): Promise<unknown>
reauthenticate(input?: { server?: string | null; url?: string | null }): Promise<{
kind: 'mcp_reauthentication_request'
server: string | null
url: string | null
authKind: 'oauth' | 'bearer' | 'none'
resourceMetadataUrl: string | null
authOptions: readonly ['oauth', 'bearer', 'none']
fields: readonly ['url', 'authKind', 'bearerToken']
message: string
}>
}
I don't expose any MCP stuff to the agent at all, just these functions. It gets a list of connected MCPs in the prompt, and it can call 'searchTools' to find any relevant tools in the server. And to execute the tool it the calls MCP.executeTool().
Then, the harness makes the MCP request on behalf of the agent using the HTTP api.
This saves a ton of tokens over normal MCP. It's definitely heavily inspired by Cloudflare Code Mode, but I've taken even that to an extreme.
Emergent properties
It's been super easy to add new features. They're most commonly just a skill, or more rarely a newly exposed function.
The most interesting one is memory. I don't need to build anything for memory. I just store memories under /memories in the file system, add a little prompt to tell the agent about memories. My files get automatically indexed and become searchable, so the agent can search memories by just searching files. I have a scheduled task that goes through memories and marks them as stale.
I can get the agent to email me reports every week. No extra work needed. It can search the web and send me emails, all it needs is a prompt telling it what to do.
Background tasks
My idea for background tasks is to ask the agent to add a "use background" directive to the function it writes. This is definitely in the training data, and has been used by a few recent projects ("use workflow" anyone?). This is still 'just javascript' and should hopefully be quite simple to implement.
Infra
The CloudFlare stack is getting really good for these kind of things. Last year it was quite rough, but now Durable Objects + Dynamic Workers are an incredibly powerful, scalable and cheap solution for building agents now. I experimented with bare metal and firecracker and things like that, but it was just a huge amount of ops.
Additional shout out to https://alchemy.run/ for making dev and deployment a breeze.
What's next?
I'm building out a product on top of the agent, which I'll hopefully be able to talk about in the next few weeks! I'm really excited to share it with everyone – it keeps impressing me.
Prior art:
https://blog.cloudflare.com/project-think/
https://blog.cloudflare.com/code-mode-mcp/
https://pi.dev/