
Serverless Straight to S3 Uploads
Handling uploads is annoying. Especially if you're taking content from users.
You usually do something like the following:
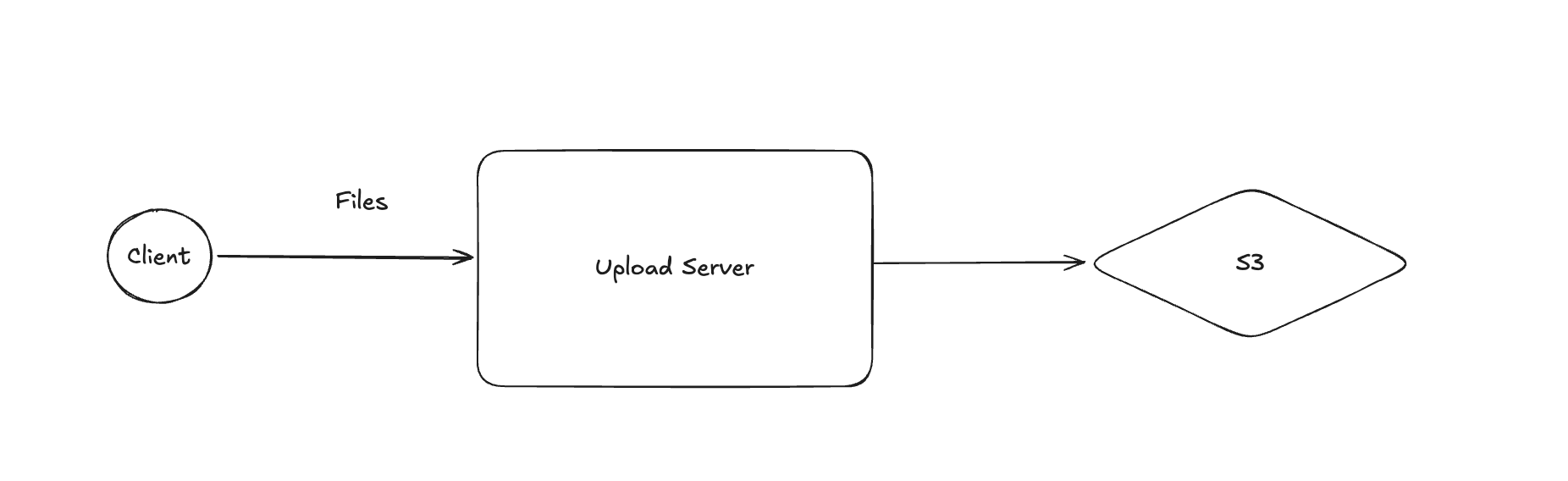
You have an upload server, your users upload to it, and then you move the file to S3. Cool. But then someone will try to upload hundreds of files at once, so you need to handle that. And suddenly you're running a ton of upload servers. The biggest bottleneck is often networking, as it's far easier to saturate the bandwidth of a low tier EC2 instance than it is to saturate the CPU - this is IO bound. Uploads also tend to be very spiky, so you're almost always overprovisioned.
We can do better.
Enter Cloudflare
With the introduction of R2, Cloudflare has a far better way of handling this.
Let's have a look at an example worker for uploading files.
export default {
async fetch(request, env) {
const url = new URL(request.url);
const key = url.pathname.slice(1);
switch (request.method) {
case "PUT":
const authenticated = checkAuth(request);
if (!authenticated) {
return new Response("Unauthorized", { status: 401 });
}
await env.MY_BUCKET.put(key, request.body);
await storeMetadata(key);
return new Response(`Put ${key} successfully!`);
default:
return new Response("Method Not Allowed", {
status: 405,
headers: {
Allow: "PUT",
},
});
}
},
};
In this case, we are authenticating the request before the upload, and afterwards we're storing some metadata in a database.
This is a fairly simple bit of code, but it has a ton of benefits. Firstly, we are able to run arbitrary code before and after the upload. Secondly, the worker never touches the body of the request, it gets directly forwarded to R2 (which is great, as workers are only limited to 128MB of memory). Thirdly, we are not managing any infrastructure ourselves. Workers will scale up and down automatically based on demand, and we only pay for the CPU usage. Since file upload is often I/O bound, this ends up being cheap.
This does open you up to Content-Type spoofing attacks, but we can trigger a job to validate the file type.
But I'm on AWS?!
Turns out there is a (very convoluted) way of getting almost all of the benefits of this approach on AWS.
It's cheaper on Cloudflare, as you are billed for the wall-clock time, rather than CPU time. If you're writing to the metadata database, you're billed for the duration of that request. So keep round trips to a minimum! Sadly you also can't run code asynchronously without the need for a queue, as there's no waitUntil alternative.
We have been running this Amazon variant in production for years. It's cheap (<$20 of compute a month at decent scale), and requires very little maintenance of the infrastructure.
I'm not going to lie though. The code needed and the complexity of the solution are a lot higher on AWS.
The limitations of Lambda
Doing this with Lambda directly is a bad idea. Firstly, you are limited to a 6MB upload size (not practical for many use cases). Secondly, you are charged for the whole duration of the upload. And thirdly, you're just buffering the upload through a low-powered server, which is not ideal. And finally, unless you put Cloudfront in front, you're not getting the benefits of their global PoP and backbone.
The solution
Cloudfront supports an S3 Bucket as an origin server. This allows us to 'sandwich' the upload by two Lambda@Edge functions. Note that Lambda@Edge is different from Lambda as it does not process the body, it only processes the headers and request details. The body itself is handled by Cloudfront, and is passed in a fairly optimal fashion to S3.
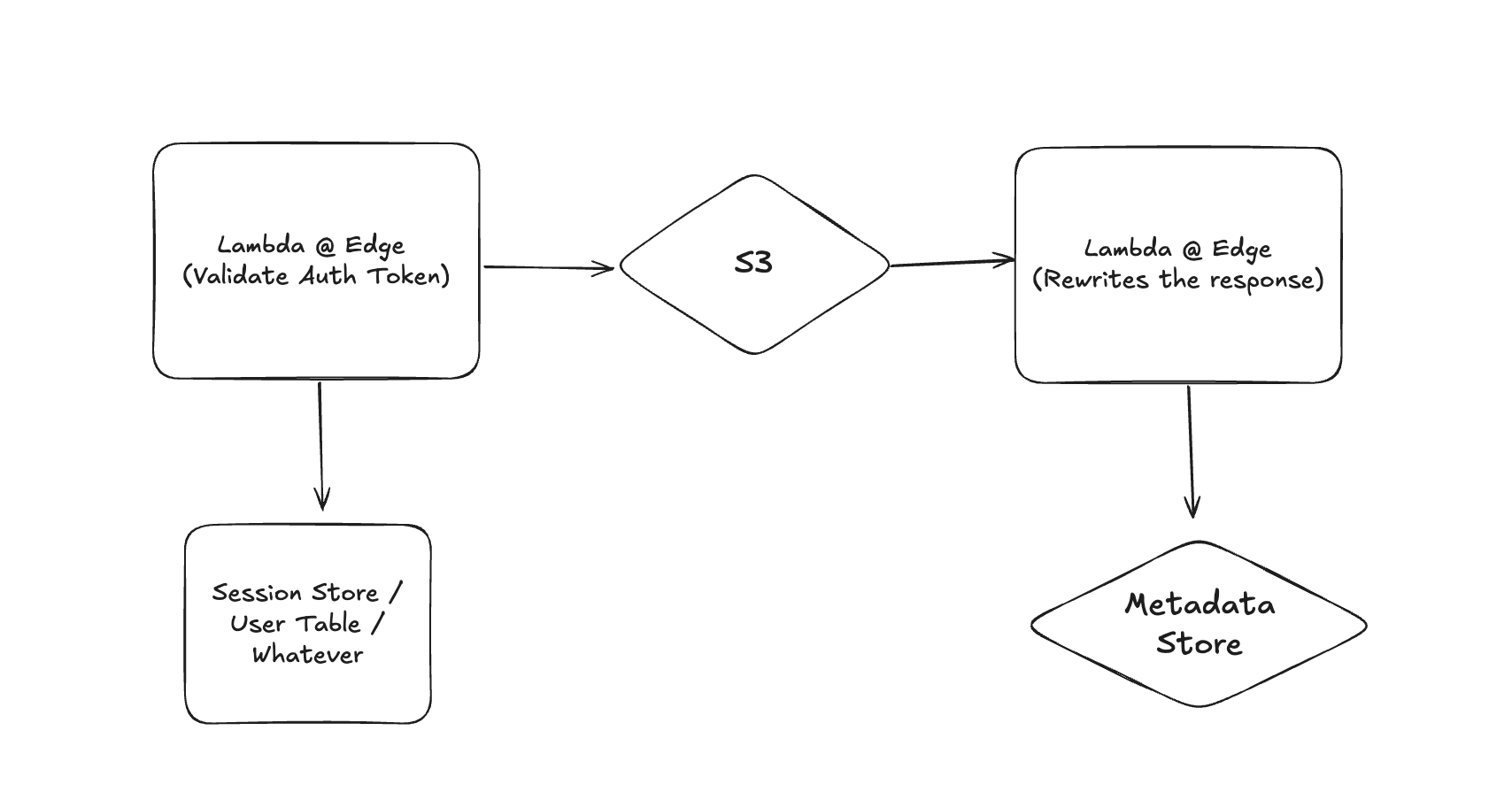
The Auth origin Lambda
exports.handler = async (event) => {
const request = event.Records[0].cf.request;
const isAuthorized = await validateAuth(request);
if (!isAuthorized) {
return {
status: '403',
statusDescription: 'Forbidden',
headers: {
'content-type': [{ key: 'Content-Type', value: 'text/plain; charset=utf-8' }],
},
body: 'Forbidden'
};
}
// authorized → continue to origin
return request;
};
Note that after this Lambda returns, you are not billed for any further compute time. The body gets passed to S3 directly, and you're not billed for the duration of the upload.
The Origin Response Lambda
exports.handler = async (event) => {
const { response, request } = event.Records[0].cf;
await updateMetadata(response);
return response;
};
Once the file is completed (you can check for any errors here too), you can store whatever metadata you want, and then return to the client. You can even rewrite the response to add additional details.
That's it! You've now replicated the single worker with 2 Edge Lambdas.
A note on Authorization
You'll need an Origin Access Control policy on your Cloudfront distribution to allow writing to your bucket. It does something funny to Authorization headers, so trying to manually authorize will cause headaches - I never really got this to work, but it was a while ago since I last tried.
S3 Signed PUTs
As Julik Tarkhanov pointed out on X, we can use S3 signed URLs here. You can use the if-none-match header or a checksum to prevent people overwriting existing files. This does require a round trip though, and you can't run arbitrary code. However, this can in theory replace the 'before upload' step by performing auth out of band. This is a great option if you're not running this on your origin or don't have some kind of auth token you can use.
You could also ping the server from the client after upload to trigger metadata storage, but I feel like that's a bit more unreliable than doing it with the Edge Lambda.
Limitations
It's not possible to modify the HTTP method of the request. So you're limited to this being a PUT. This can make it a bit awkward if you want POST-like semantics on your endpoint. And there's no way of redirecting a POST to a PUT request, so you can't use standard HTTP either.
Again, you're billed for duration, not CPU time - so if you're doing network requests, they need to be fast.
Best of both worlds?
Note that it is possible to use a Cloudflare Worker in front of an S3 Bucket. This gives you all the ergonomics and cost benefits of workers, coupled with the reliability of S3. R2 has a whole bunch of weird limitations which I won't dive into detail on (including an undocumented concurrent request limit).
In this case you can just use something like AWS4Fetch to upload to your S3 bucket. Unless you explicitly read the body in your worker, it always streams it through to the origin when you do a 'fetch' request.